(网经社讯)2019中国人工智能产业年会重磅发布《2019人工智能发展报告》(Report of Artificial Intelligence Development 2019)。唐杰教授代表报告编写相关单位就《2019人工智能发展报告》主要内容进行了介绍。报告力图综合展现中国乃至全球人工智能重点领域发展现状与趋势,助力产业健康发展,服务国家战略决策。
报告概要视频报告依托于AMiner平台数据资源及技术挖掘成果生成相关数据报告及图表,邀请清华大学、同济大学等高校专家解读核心技术及提出观点建议,在一定程度上保证了报告的科学性和权威性。
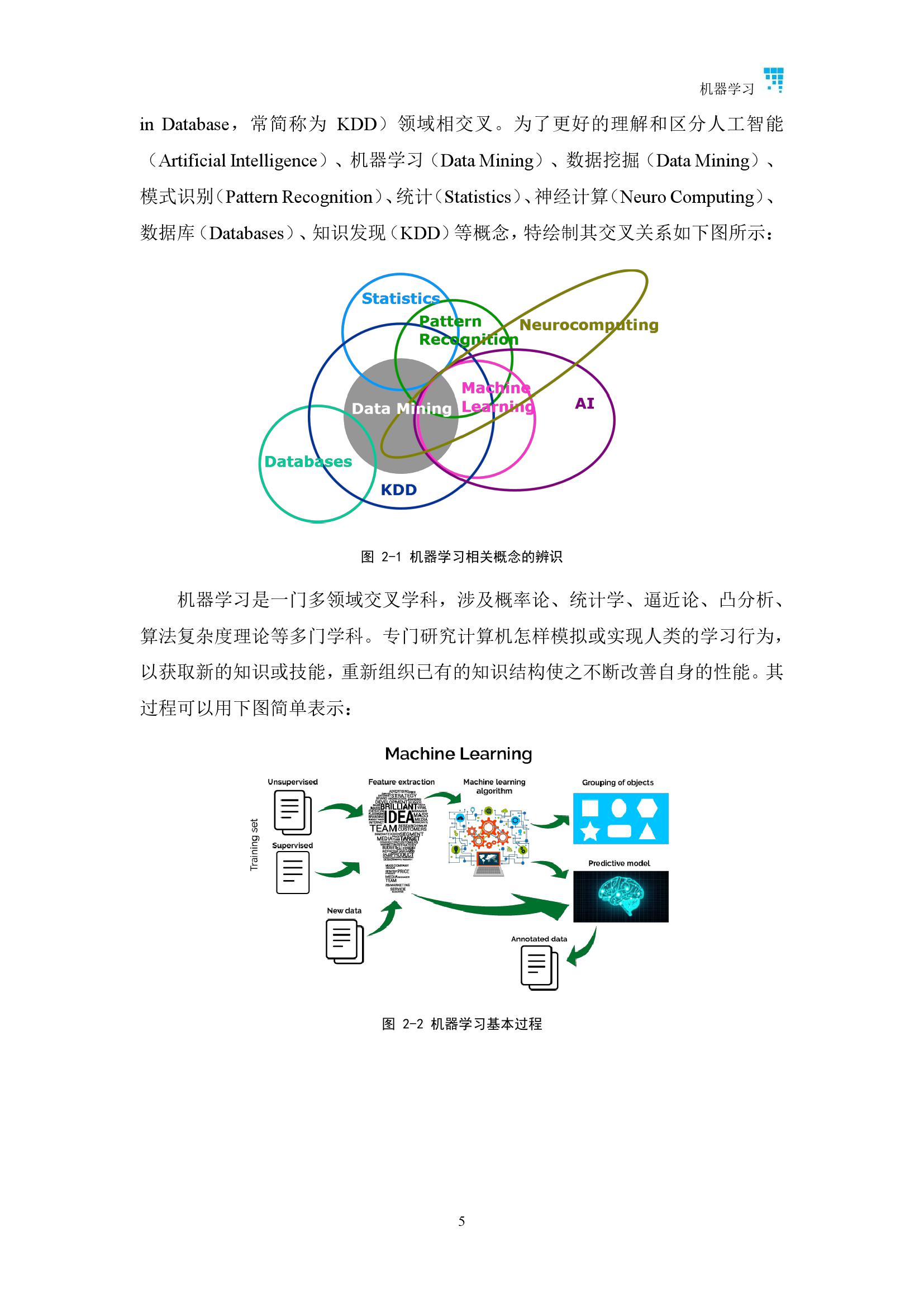
报告涉及AI 13个子领域
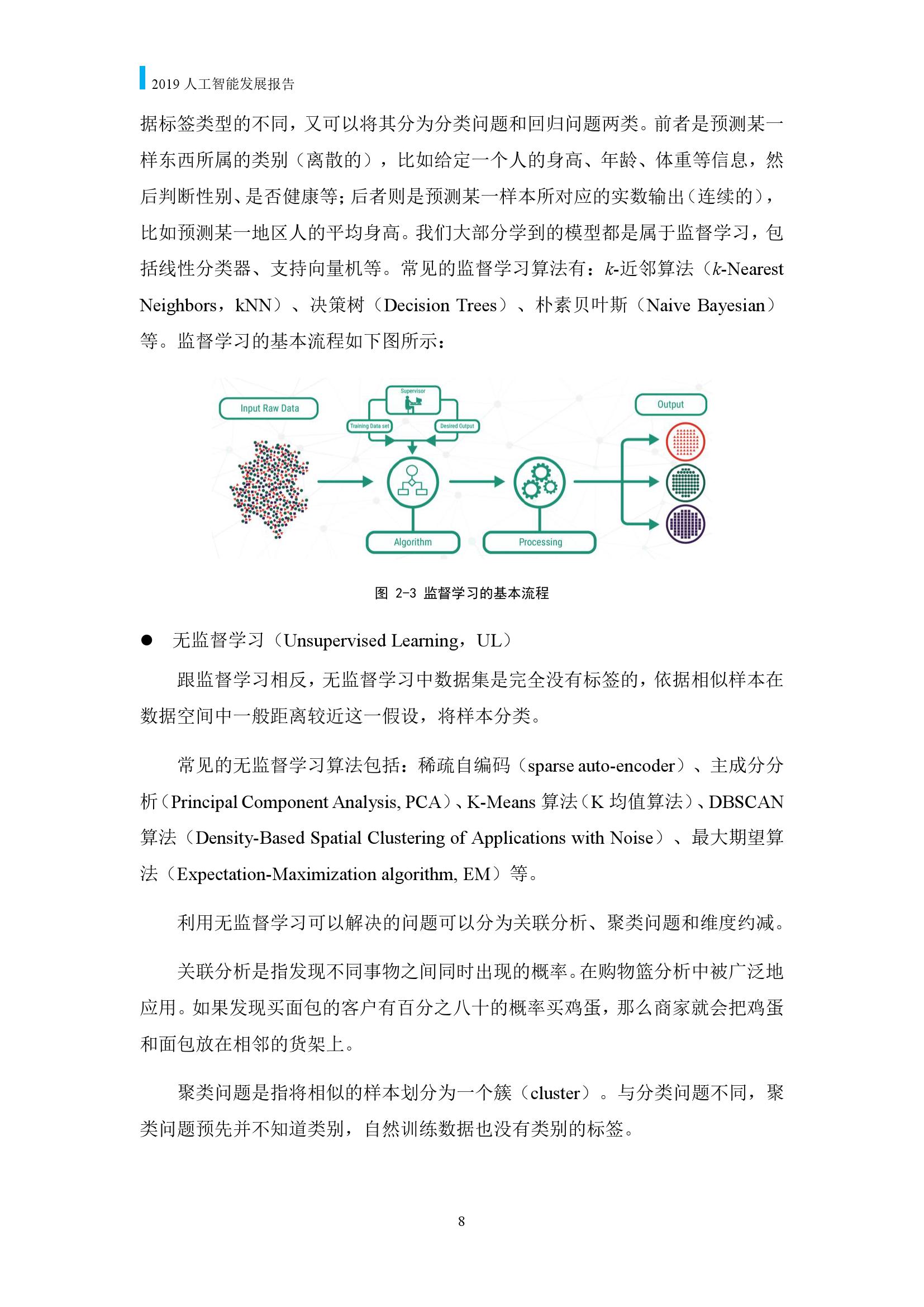
内容涵盖了人工智能13个子领域,包括:机器学习、知识工程、计算机视觉、自然语言处理、语音识别、计算机图形学、多媒体技术、人机交互、机器人、数据库技术、可视化、数据挖掘、信息检索与推荐。
报告基本框架如上图所示,包括领域概念阐释、发展历史梳理、人才概括、关键论文解读以及相应领域的前沿进展。
1、报告呈现两大亮点
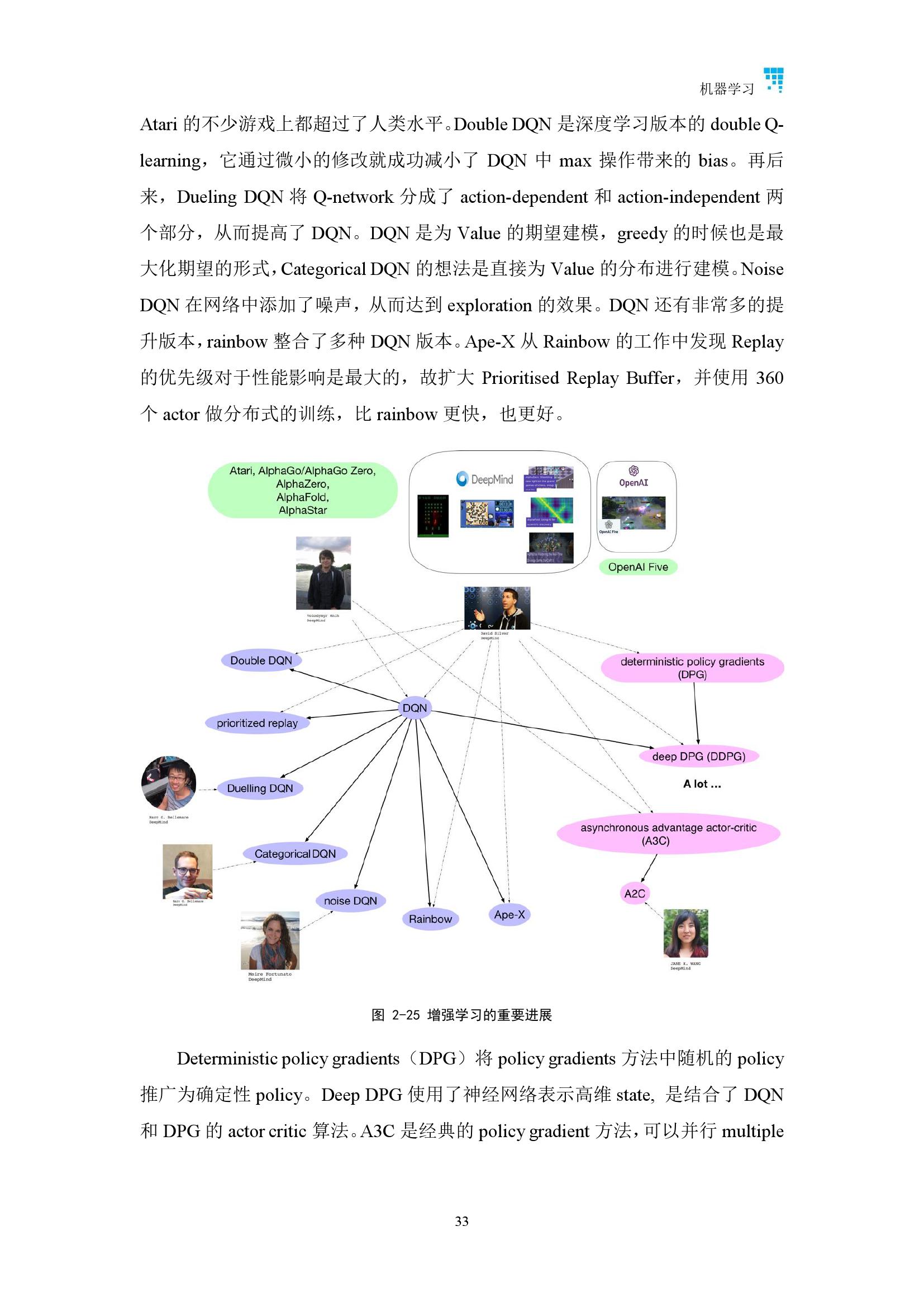
唐杰教授介绍,“该报告对人工智能每一个子领域进行了详细的分析,包括基本概念、发展历史、人才概况、代表性论文解读和前沿技术进展。相比于2018年的人工智能发展报告,具有两方面亮点,一方面体现在「AI技术的近期发展」,另一方面体现在「人才脉络一网打尽」。亮点一:AI技术的近期发展唐杰教授以 “深度学习”为例做了详细阐述。深度学习是近10年机器学习领域发展最快的一个分支,由于其重要性,Geoffrey Hinton、Yann Lecun、Yoshua Bengio 三位教授因此同获2018年图灵奖。深度学习模型的发展可以追溯到1958年的感知机(Perceptron)。1943年神经网络就已经出现雏形(源自NeuroScience),1958年研究认知的心理学家Frank发明了感知机,当时掀起一股热潮。后来Marvin Minsky(人工智能大师)和Seymour Papert发现感知机的缺陷:不能处理异或回路等非线性问题,以及当时存在计算能力不足以处理大型神经网络的问题,于是整个神经网络的研究进入停滞期。最近30年来深度学习取得了快速发展。《2019人工智能发展报告》罗列了深度学习的四个主要脉络,最上层是卷积网络,中间层是无监督学习脉络,再下面一层是序列深度模型发展脉络,最底层是增强学习发展脉络。这四条脉络全面展示了“深度学习技术”的发展近况。
深度学习模型最近若干年的重要进展第一个发展脉络(上图浅紫色区域)以计算机视觉和卷积网络为主。这个脉络的进展可以追溯到1979年,Fukushima 提出的Neocognitron。该研究给出了卷积和池化的思想。1986年Hinton提出的反向传播训练MLP(之前也有几个类似的研究),该研究解决了感知机不能处理非线性学习的问题。1998年,以Yann LeCun为首的研究人员实现了一个七层的卷积神经网络LeNet-5以识别手写数字。现在普遍把Yann LeCun的这个研究作为卷积网络的源头,但其实在当时由于SVM的迅速崛起,这些神经网络的方法还没有引起广泛关注。真正使得卷积神经网络登上大雅之堂的事件是2012年Hinton组的AlexNet(一个设计精巧的CNN)在ImageNet上以巨大优势夺冠,这引发了深度学习的热潮。AlexNet在传统CNN的基础上加上了ReLU、Dropout等技巧,并且网络规模更大。这些技巧后来被证明非常有用,成为卷积神经网络的标配,被广泛发展,于是后来出现了VGG、GoogLenet等新模型。2016年,青年计算机视觉科学家何恺明在层次之间加入跳跃连接,提出残差网络ResNet。ResNet极大增加了网络深度,效果有很大提升。一个将这个思路继续发展下去的是近年的CVPR Best Paper中黄高提出的DenseNet。在计算机视觉领域的特定任务出现了各种各样的模型(Mask-RCNN等)。2017年,Hinton认为反向传播和传统神经网络还存在一定缺陷,因此提出Capsule Net,该模型增强了可解释性,但目前在CIFAR等数据集上效果一般,这个思路还需要继续验证和发展。第二个发展脉络(上图浅绿色区域)以生成模型为主。传统的生成模型是要预测联合概率分布P(x, y)。机器学习方法中生成模型一直占据着一个非常重要的地位,但基于神经网络的生成模型一直没有引起广泛关注。Hinton在2006年的时候基于受限玻尔兹曼机(RBM,一个19世纪80年代左右提出的基于无向图模型的能量物理模型)设计了一个机器学习的生成模型,并且将其堆叠成为Deep Belief Network,使用逐层贪婪或者wake-sleep的方法训练,当时模型的效果其实并没有那么好。但值得关注的是,正是基于RBM模型Hinton等人开始设计深度框架,因此这也可以看做深度学习的一个开端。Auto-Encoder也是上个世纪80年代Hinton就提出的模型,后来随着计算能力的进步也重新登上舞台。Bengio等人又提出了Denoise Auto-Encoder,主要针对数据中可能存在的噪音问题。Max Welling(这也是变分和概率图模型的高手)等人后来使用神经网络训练一个有一层隐变量的图模型,由于使用了变分推断,并且最后长得跟Auto-Encoder有点像,被称为Variational Auto-Encoder。此模型中可以通过隐变量的分布采样,经过后面的Decoder网络直接生成样本。生成对抗模型GAN(Generative Adversarial Network)是2014年提出的非常火的模型,它是一个通过判别器和生成器进行对抗训练的生成模型,这个思路很有特色,模型直接使用神经网络G隐式建模样本整体的概率分布,每次运行相当于从分布中采样。后来引起大量跟随的研究,包括:DCGAN是一个相当好的卷积神经网络实现,WGAN是通过维尔斯特拉斯距离替换原来的JS散度来度量分布之间的相似性的工作,使得训练稳定。PGGAN逐层增大网络,生成逼真的人脸。第三个发展脉络(上图橙黄色区域)是序列模型。序列模型不是因为深度学习才有的,而是很早以前就有相关研究,例如有向图模型中的隐马尔科夫HMM以及无向图模型中的条件随机场模型CRF都是非常成功的序列模型。即使在神经网络模型中,1982年就提出了Hopfield Network,即在神经网络中加入了递归网络的思想。1997年Jürgen Schmidhuber发明了长短期记忆模型LSTM(Long-Short Term Memory),这是一个里程碑式的工作。当然,真正让序列神经网络模型得到广泛关注的还是2013年Hinton组使用RNN做语音识别的工作,比传统方法高出一大截。在文本分析方面,另一个图灵奖获得者Yoshua Bengio在SVM很火的时期提出了一种基于神经网络的语言模型(当然当时机器学习还是SVM和CRF的天下),后来Google提出的word2vec(2013)也有一些反向传播的思想,最重要的是给出了一个非常高效的实现,从而引发这方面研究的热潮。后来,在机器翻译等任务上逐渐出现了以RNN为基础的seq2seq模型,通过一个Encoder把一句话的语义信息压成向量再通过Decoder转换输出得到这句话的翻译结果,后来该方法被扩展到和注意力机制(Attention)相结合,也大大扩展了模型的表示能力和实际效果。再后来,大家发现使用以字符为单位的CNN模型在很多语言任务也有不俗的表现,而且时空消耗更少。Self-attention实际上就是采取一种结构去同时考虑同一序列局部和全局的信息,Google有一篇很有名的文章“attention is all you need”把基于Attention的序列神经模型推向高潮。当然2019年ACL上同样有另一篇文章给这一研究也稍微降了降温。第四个发展脉络(上图粉色区域)是增强学习。这个领域最出名的当属Deep Mind,图中标出的David Silver博士是一直研究RL的高管。Q-learning是很有名的传统RL算法,Deep Q-learning将原来的Q值表用神经网络代替,做了一个打砖块的任务。后来又应用在许多游戏场景中,并将其成果发表在Nature上。Double Dueling对这个思路进行了一些扩展,主要是Q-Learning的权重更新时序上。DeepMind的其他工作如DDPG、A3C也非常有名,它们是基于Policy Gradient和神经网络结合的变种。大家都熟知的AlphaGo,里面其实既用了RL的方法也有传统的蒙特卡洛搜索技巧。Deep Mind后来提出了一个使用AlphaGo的框架,但通过主学习来玩不同(棋类)游戏的新算法Alpha Zero。唐杰教授表示:“报告还展示了近一两年深度学习的发展热点,比如去年谷歌Bert一经发布,就引起了整个产业界和学术界的轰动,或将影响深度学习乃至整个机器学习的未来。报告对Bert的相关研究进行了详细梳理,无论是最新还是最经典的研究都进行了整理,可以让读者从相关研究中窥见未来。”
通过AMiner可生成趋势分析
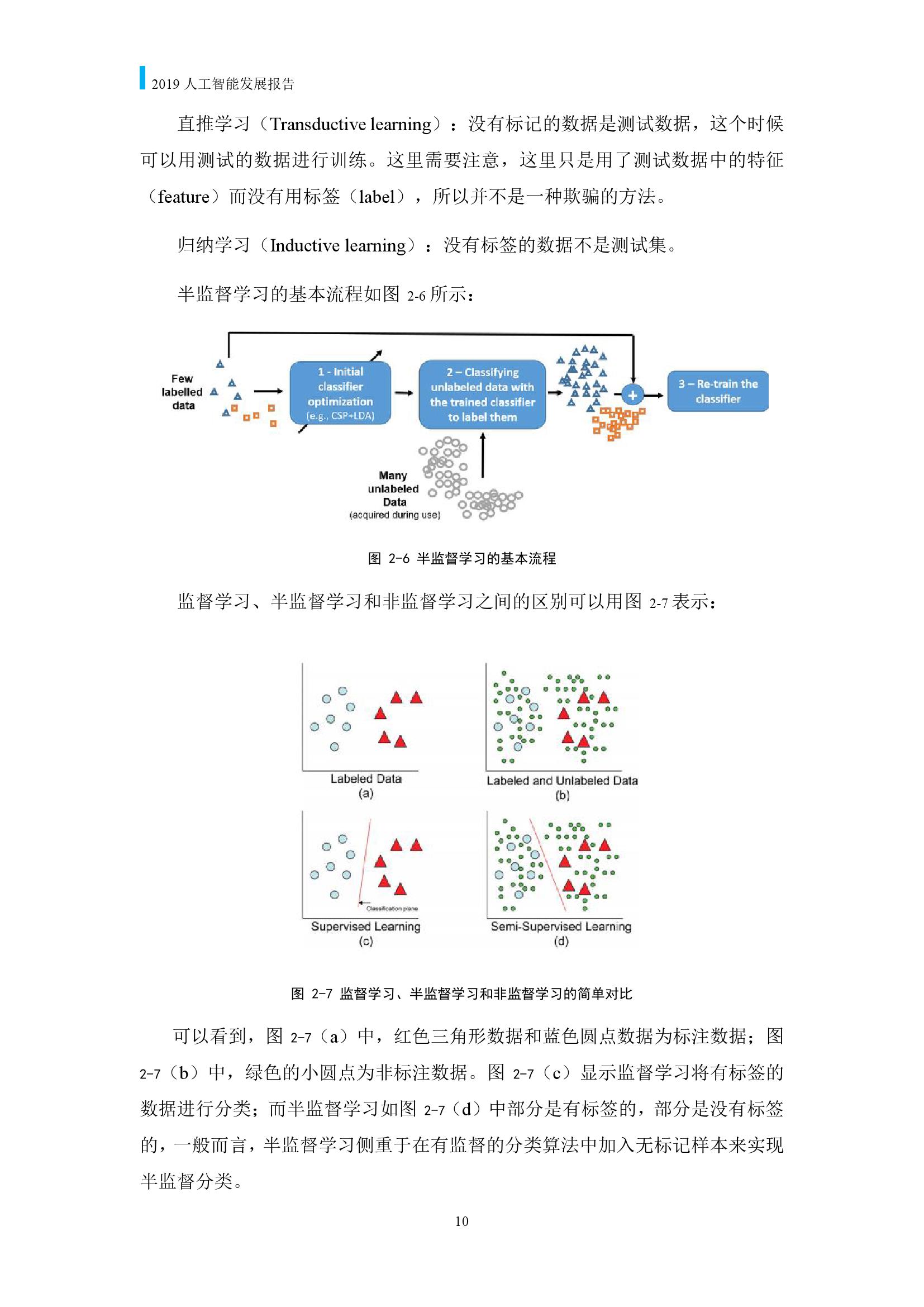
亮点一还体现在详细的知识图谱中。
唐杰教授指出,“每一个领域都有丰富的知识图谱架构,从知识图谱可以一览整个领域的发展脉络。同时,通过这样的知识图谱还可以进一步开展包含主题分析、热点话题分析等多层次的趋势分析、趋势洞察等”。
亮点二:人才脉络一网打尽唐杰教授做了简单分析。报告通过对人工智能顶级期刊/会议近10年论文及相关学者数据的深度挖掘分析,研究了各领域学者在世界及我国的分布规律。
同时,报告进一步统计分析了各领域学者性别比例、h-index分布以及中国在各领域的合作情况,通过统计中外合作论文中作者的单位信息,将作者映射到各个国家中,进而统计出中国与各国之间合作论文的情况。
唐杰教授介绍说,“我们还开发了人才精准画像和超大规模知识图谱,通过数据挖掘,首先找到作者,对每一个作者进行深度的人才画像,不仅能看到每一个学者的联系方式、职位、单位信息,还有职位变迁、兴趣变化等等。”
另一方面,通过对学者的精准画像,针对每一个领域的专家全球分布图和国内分布图可以进行国内外对比分析,甚至可以开展人才流失分析,比如分析一个国家人才引进和人才流出的情况是盈利还是亏损等。
最后,唐杰教授对报告撰写的数据支持平台AMiner进行了介绍。AMiner系统自2006年上线以来已经运行了十多年,它是一个知识驱动科技情报挖掘平台,包含超过三亿篇论文和一亿多科研人员数据,能够提供包括专家发现、智能推荐、机构评估、人才地图和科技趋势分析等多种服务。AMiner平台诸多功能已在科技部、教育部、北京市科委、自然基金委等多家单位应用,希望AMiner平台未来能有更多方面的应用前景。
2、为智能产业发展助力献策当前,我国进入科技高速发展期,人工智能作为科技领域冉冉升起的新星,受到国家的高度重视。在多层次战略规划的指导下,无论是学术界还是产业界,我国在人工智能国际同行中均有不错的表现。我国人工智能的发展已驶入快车道。在这个阶段下,能够推动技术突破和创造性应用的高端人才对人工智能的发展起着至关重要的作用。
此次发布的《2019人工智能发展报告》,通过深入探讨研究方法,对近年来的热点及前沿技术进行了深度解读,展现最新研究成果,内容在聚焦当下人工智能发展现状的同时,并作出技术性分析,更对相关领域的未来发展方向进行了展望,为读者了解近期人工智能相关领域的发展动向、基础及应用研究的代表性成果提供信息窗口。该报告是集严谨性、综合性、技术性、前瞻性为一体的专业领域报告,具有极高的学术价值和参考价值。不仅有利于推进我国人工智能的研究探索,同时还对国家洞悉人工智能发展态势、实施人工智能发展策略起到重要参考借鉴。
































(来源:199IT 编选:网经社)